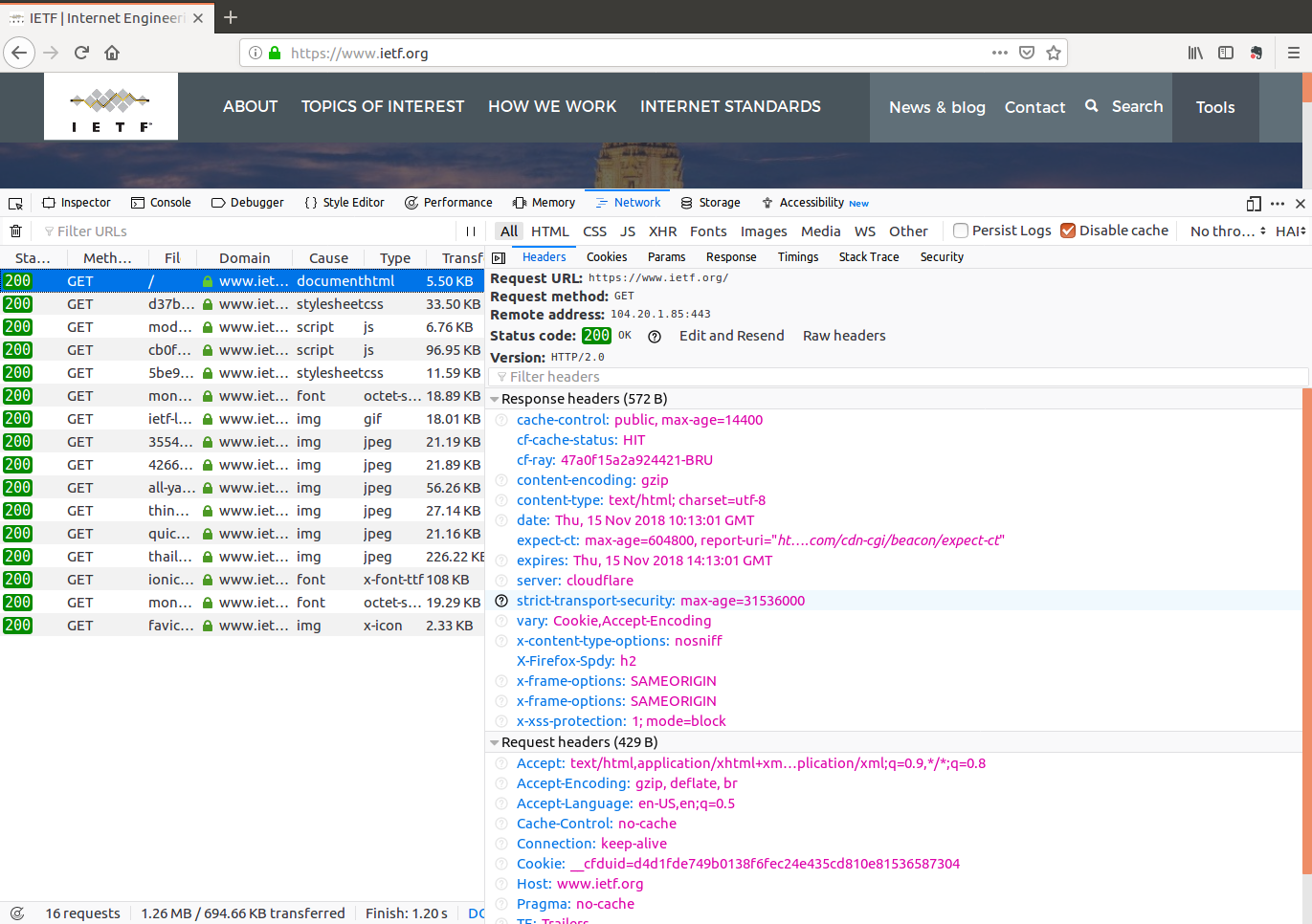
A first analysis of an HTTP server
Networking students can learn a lot about Internet protocols by analyzing how they are actually deployed. For several years, Computer Science students at UCLouvain have analyzed different websites within their introductory networking course. This project considers several key Internet protocols, DNS, HTTP, TLS and TCP. In this post, we briefly analyze how HTTP is used on some websites as a starting point for these students.
The simplest way to analyze how a web server uses HTTP is to start with the developer extensions that are included in most web browsers. In this post, we use firefox a very popular and open-source web browser.
Let us start the analysis with the http://cnp3book.info.ucl.ac.be website. This website is hosted on a single server located in Louvain-la-Neuve and it uses a very simple configuration. When rendered with firefox, this web page is displayed as follows.
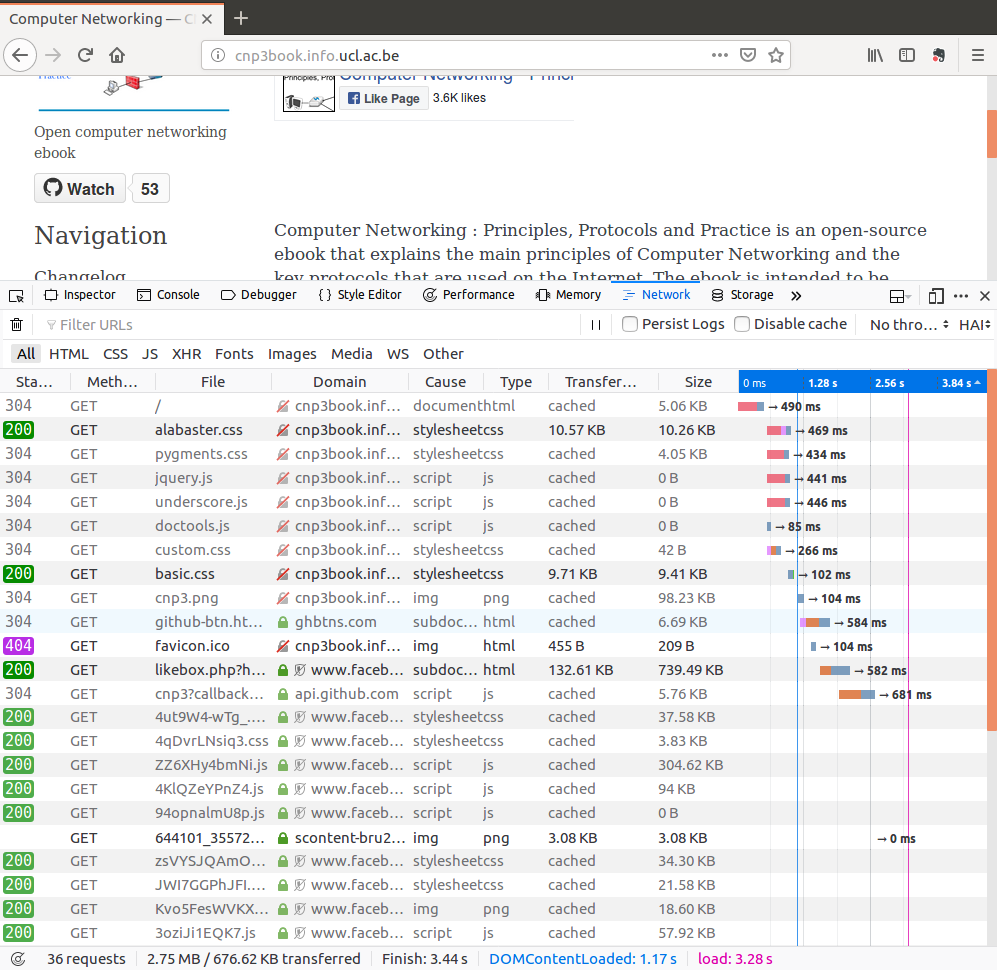
The interesting information about the website comes from the developer tools (Tools->Web Developper->Toggle Tools) and more precisely the Network component. Let us first select Disable Cache to force the browser to reload all the elements that compose the page.
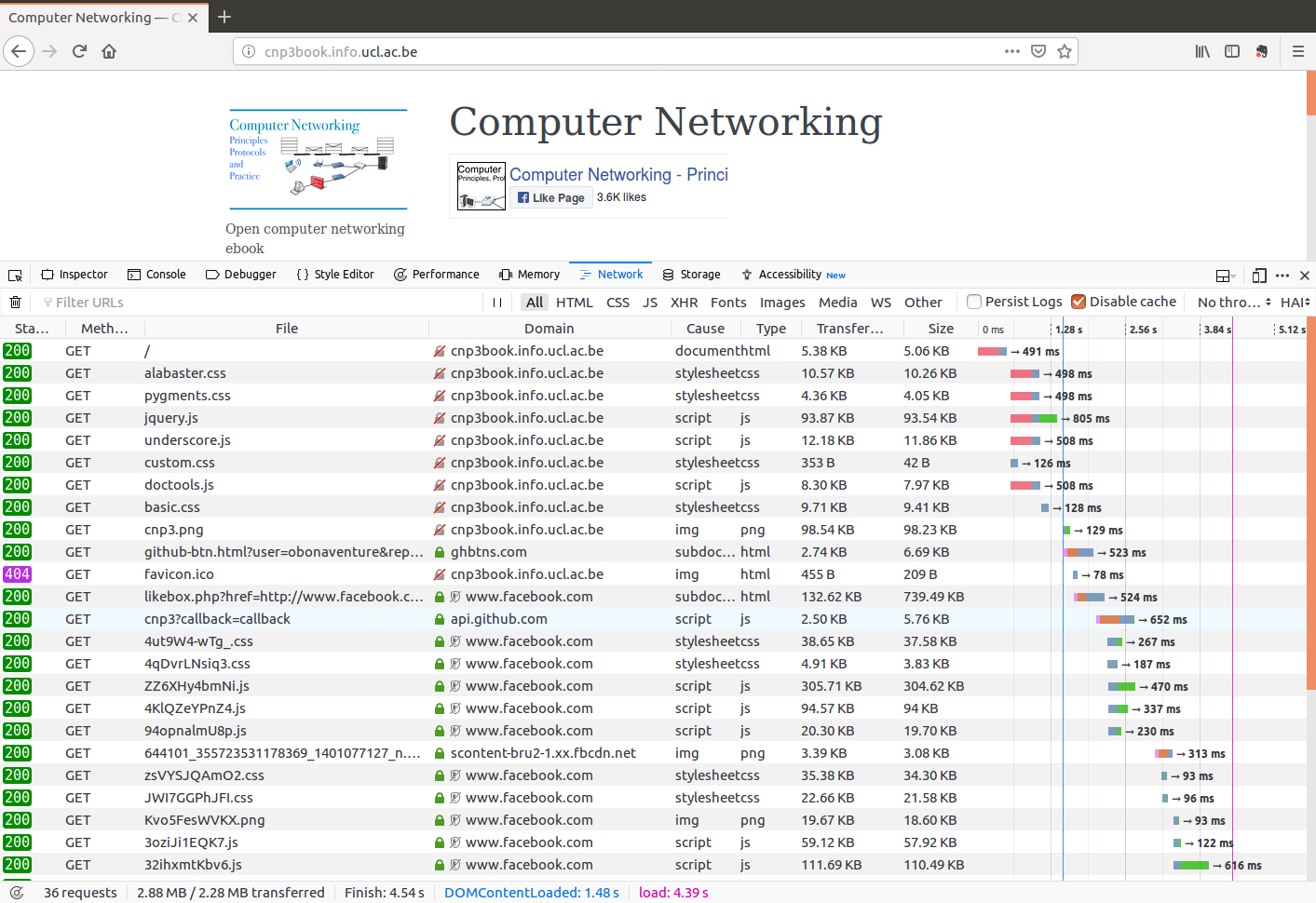
There are several interesting points to note in the analysis provided by firefox. The first point to notice is the number of websites that are contacted to display the above web page. Unsurprisingly, the first request is sent to http://cnp3book.info.ucl.ac.be. The file is short (5.38 KBytes) and is retrieved in 491 msec. Its Status is 200 which is the standard HTTP Status for a successful web request. We can observe the request in more details by clicking on the first line.
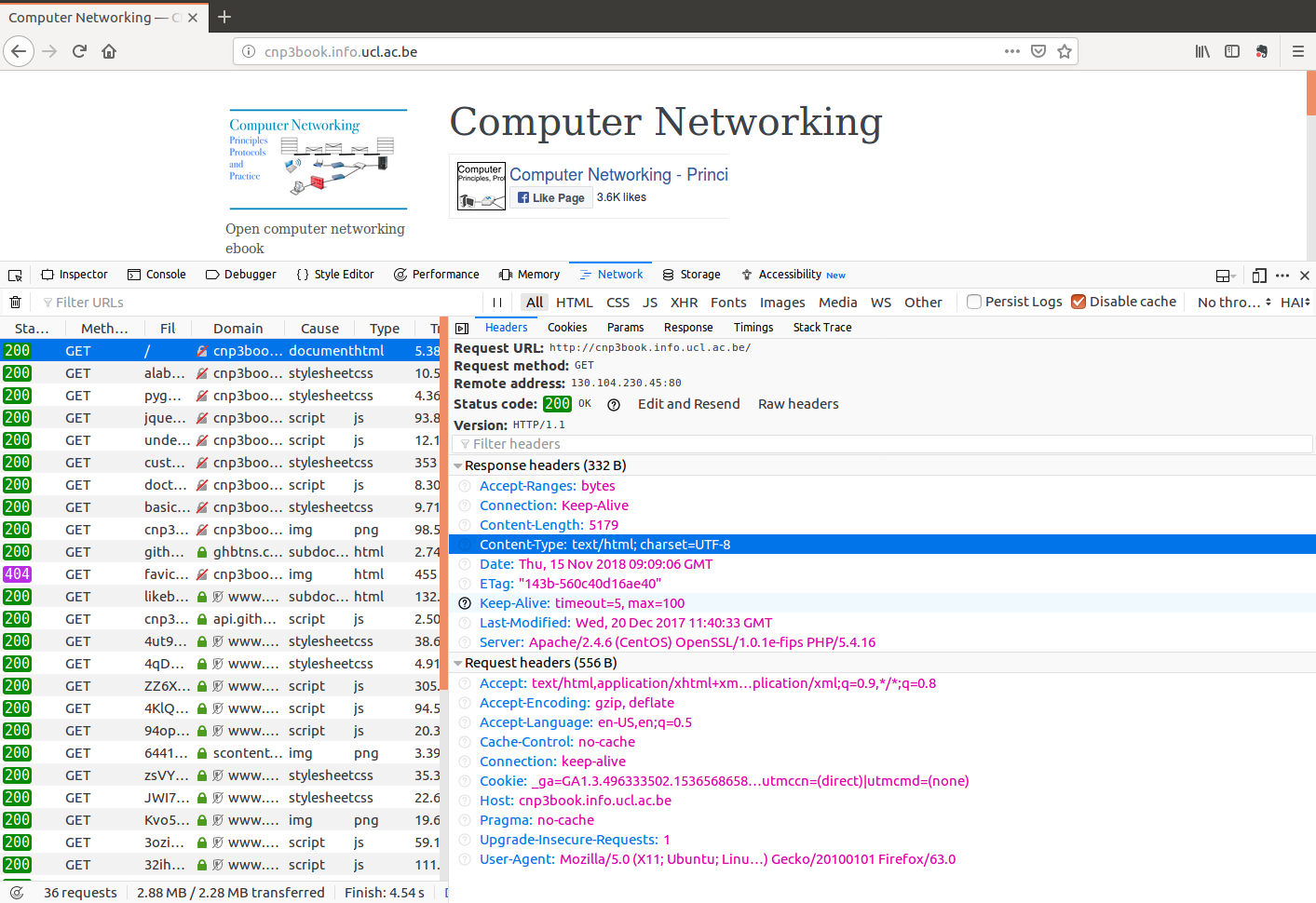
This request has been served by using HTTP/1.1. We observe that the client and the server agreed to continue to use the underlying TCP connection (Connection: Keep-Alive) and that the web page has not been modified since Dec. 20th, 2017. It is also possible to look at the raw HTTP headers and even change them manually before re-sending them.
The last web object that is requested from http://cnp3book.info.ucl.ac.be is http://cnp3book.info.ucl.ac.be/favicon.ico. This file is supposed to be a small icon that represents the website and can be shown in the browser bar. The owner of the website did not provide this icon and thus the website returns a 404 Status code.
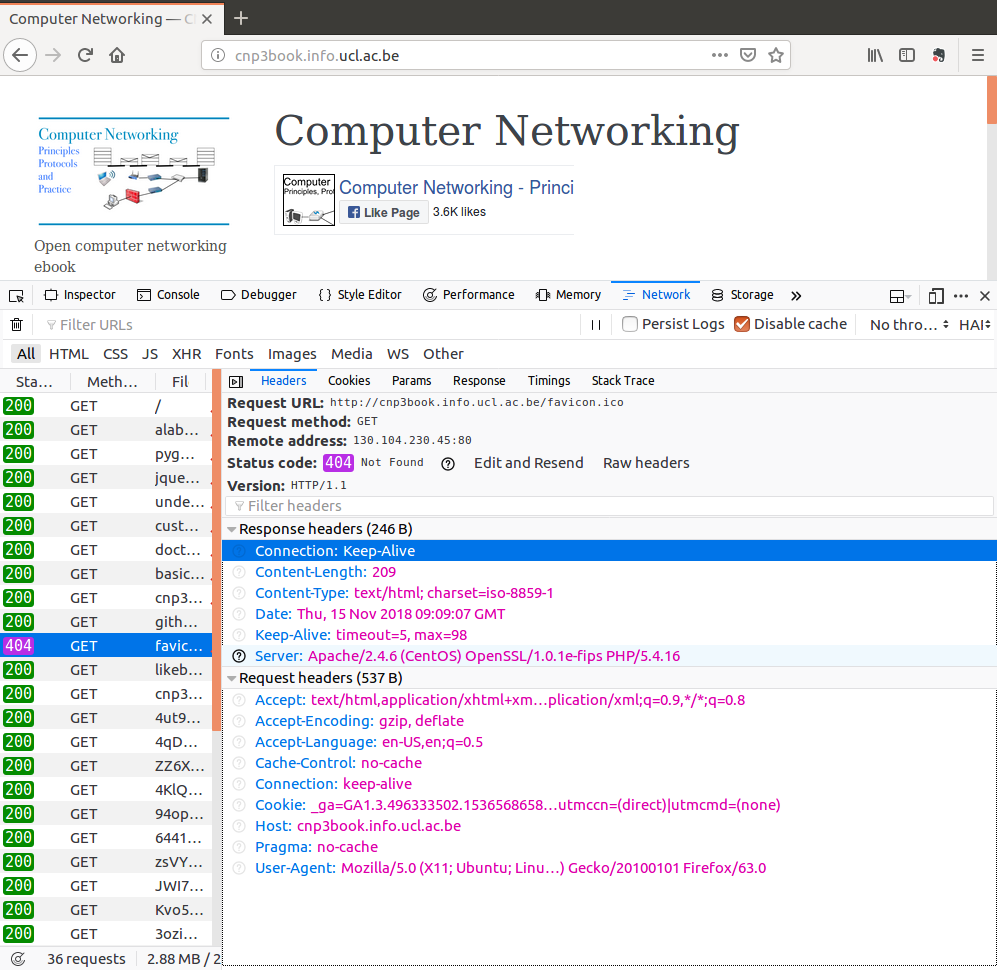
A last point to note about these objects is that they were retrieved over HTTP and firefox shows them as insecure with a gray lock icon and a red line.
Once the HTML, css and javascript objects have been downloaded from the main website, the browser starts to retrieve objects from other websites that are referenced in the HTML file.
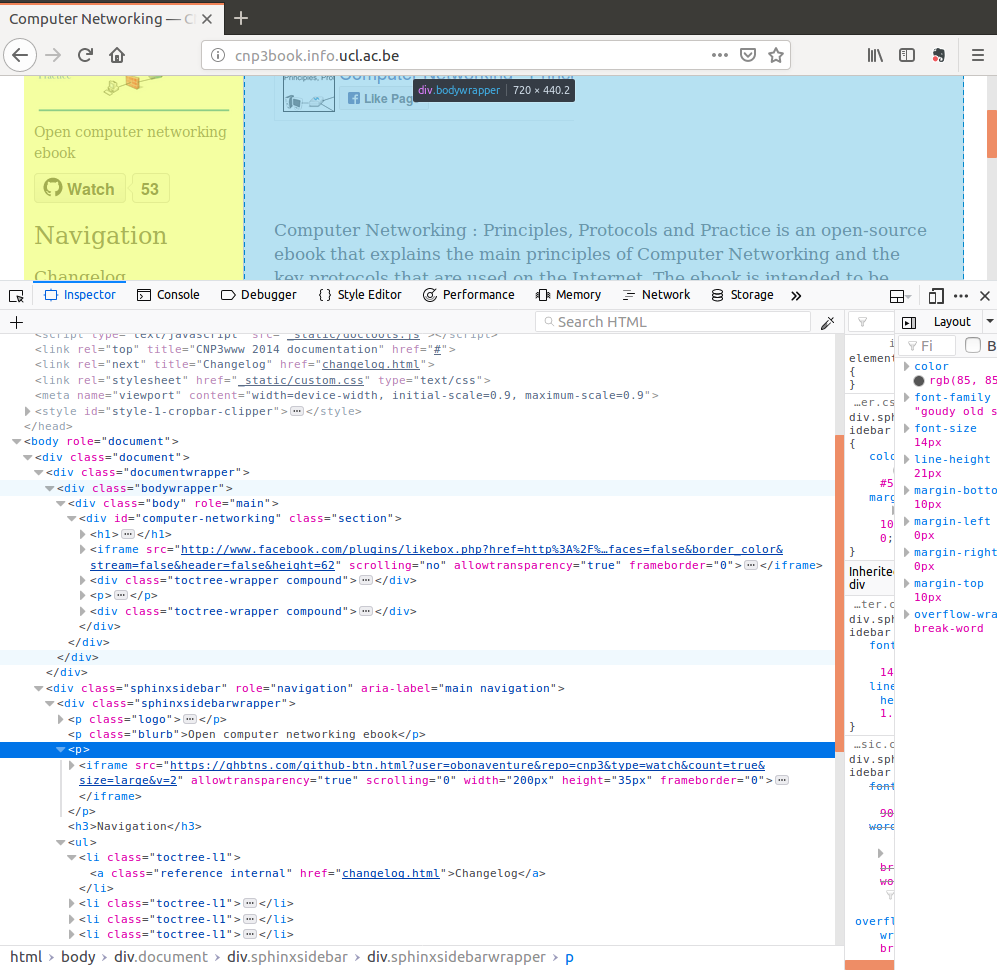
A closer look at the HTML file shown above reveals that it contains two iframes. The first one loads the facebook like button and the second the github button.
The github button is pretty lightweight, there are two objects that are retrieved from websites owned by github: https://ghbtns.com/github-btn.html?user=obonaventure&repo=cnp3&type=watch&count=true&size=large&v=2 and https://api.github.com/repos/obonaventure/cnp3?callback=callback. Let us look at the first of these requests to look at timing information. This request took 569 msec.
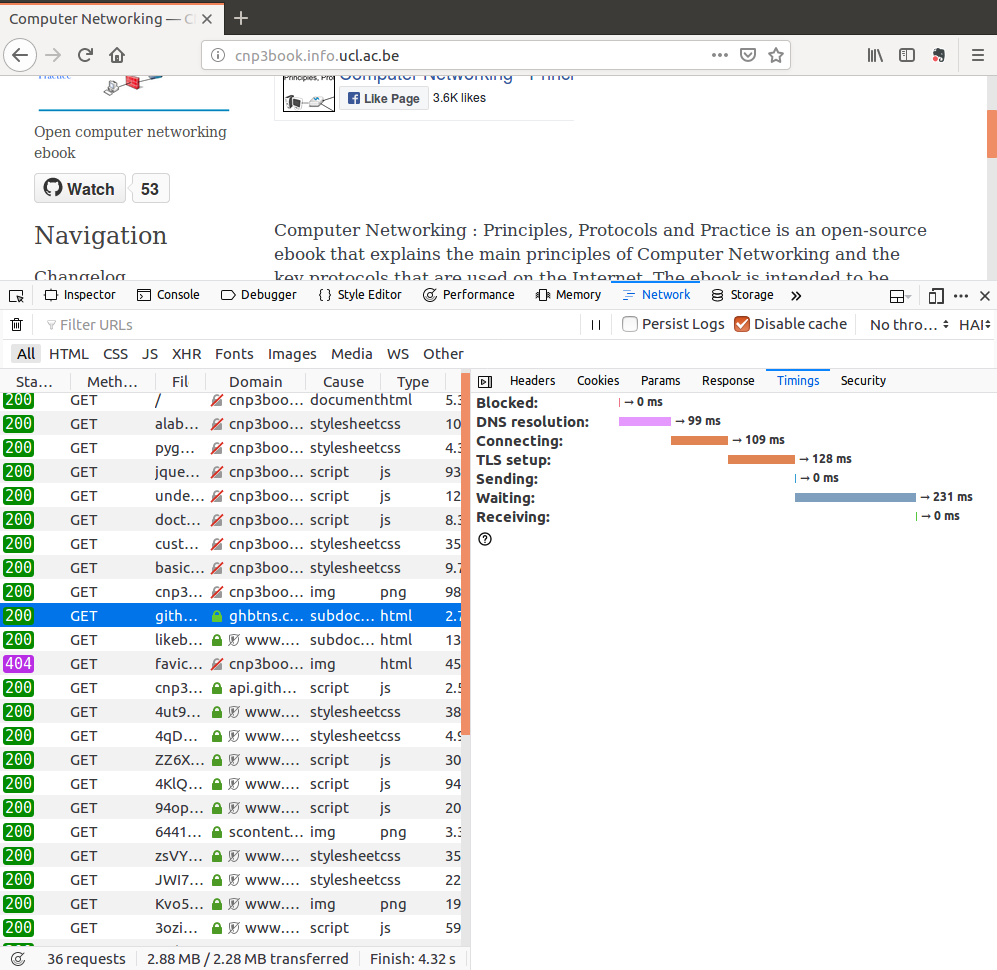
However, this delay can be decomposed in several parts. First, the DNS resolution, 99 msec. Second, the time required to establish the TCP connection to the server. Third, the time required to create the TLS session to secure the connection. Finally the transmission of the request and the reception of the response. Major websites try to minimize those delays.
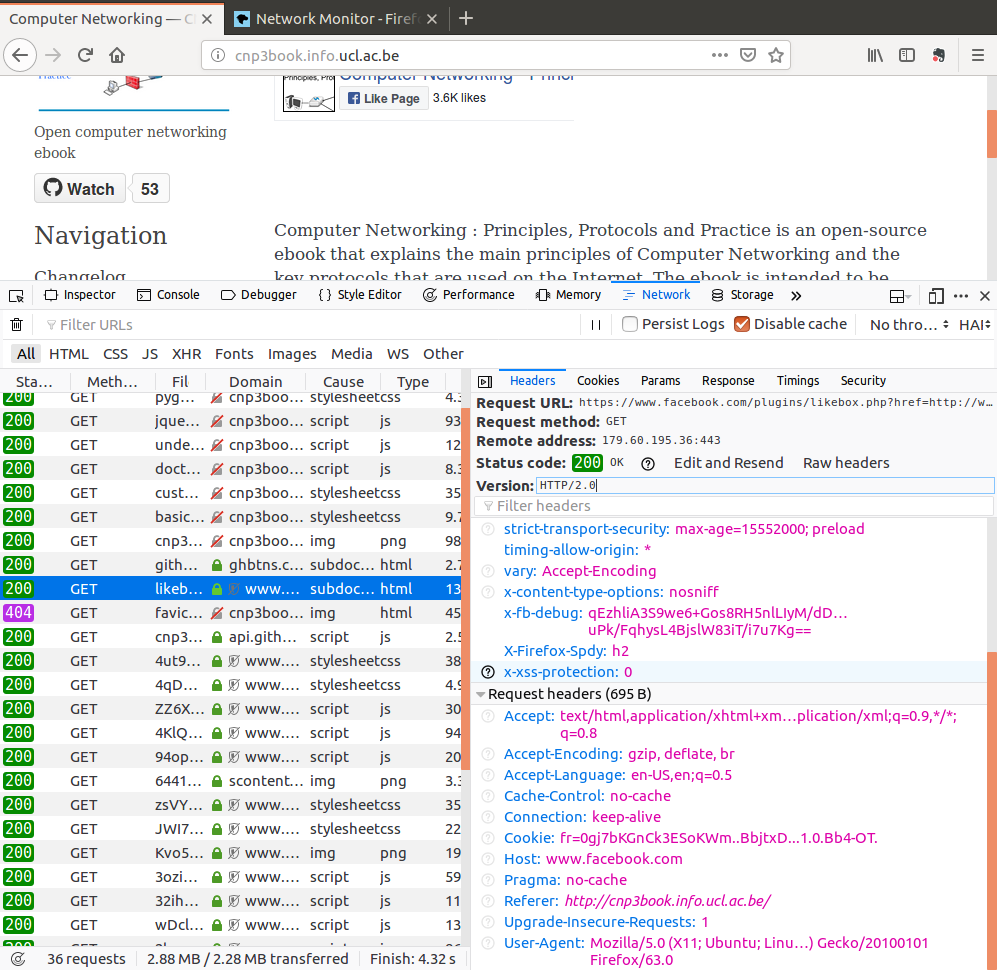
Let us now look at the first of the dozens of requests sent by our browser to facebook servers. This request is sent over HTTP/2.0. It contains several interesting elements inside the request and the response headers. The request contains a cookie which allows facebook to identify the user. As this browser has never been used to log on facebook, facebook does not match it to an actual user name. For any of the HTTP header, a click on the question mark icon links to the firefox manual pages that provide additional information about the standardized headers. You might observe non-standardized ones and very strange headers on some websites.
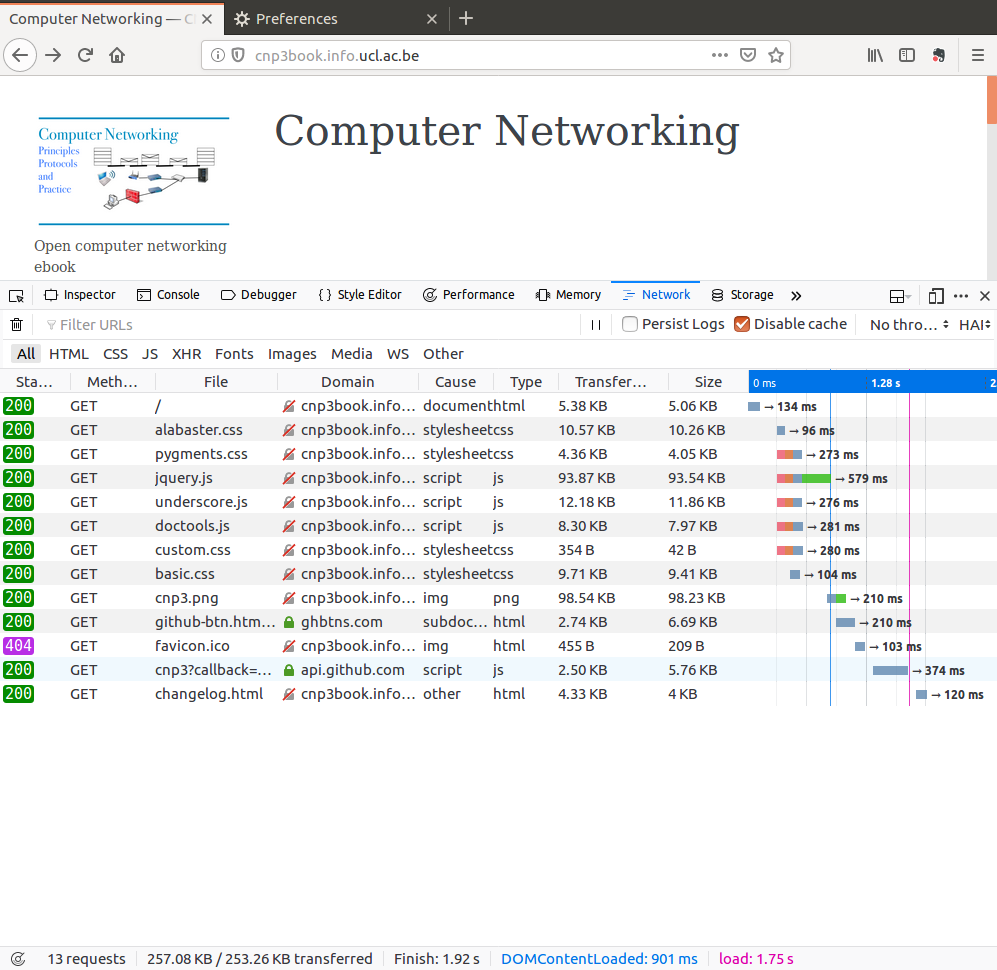
If we enable the cache and reload the website, we observe that many of the web objects can be retrieved from the cache and do not need to be downloaded again. The web server returns a 304 Status for this cached objects. It is interesting to note that none of the facebook web objects are cacheable…
Another interesting experiment is to test the recent privacy features of firefox. Firefox can recognize some tracking websites and disables them. If we enable this feature, firefox does not download anymore the facebook objects, but still the github button. The content of the web page changes slightly, but it is downloaded much more quickly than with all the facebook objects.
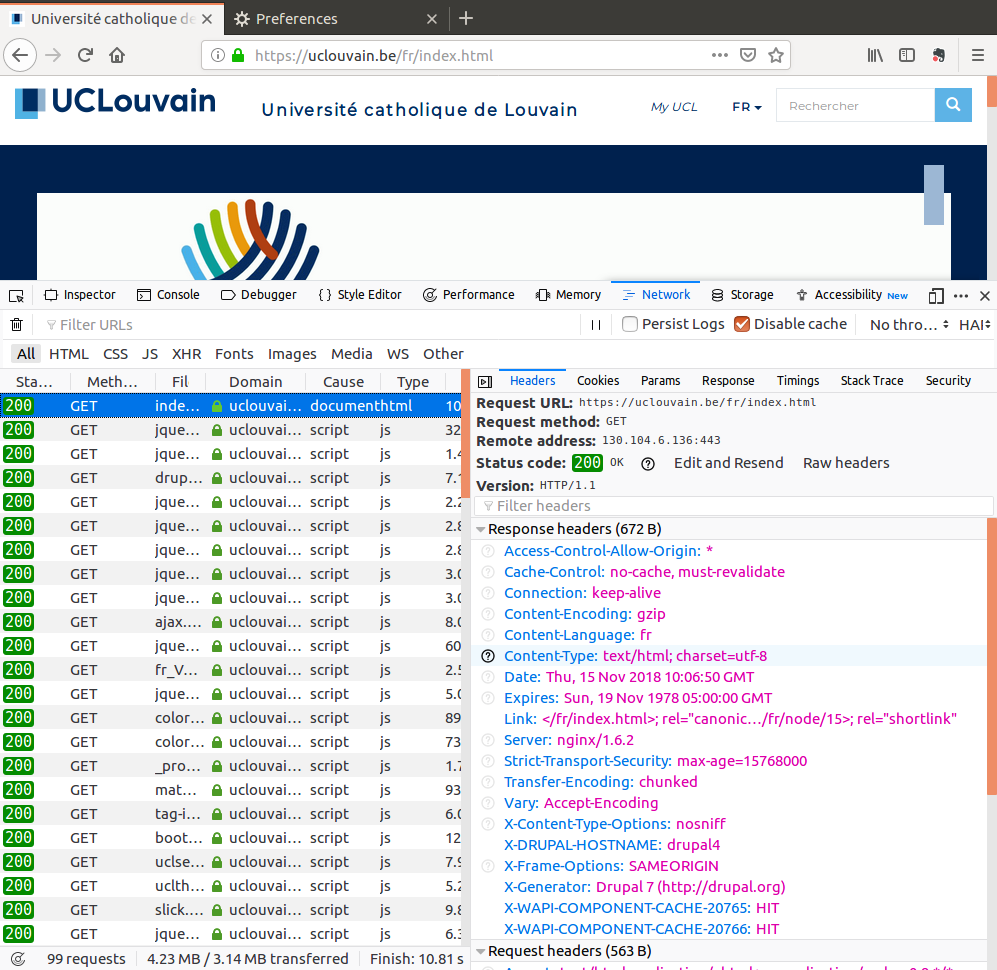
The UCLouvain web site is a rare example of a website that serves all its contents from its own servers without relying on third party services for fonts, tracking, …
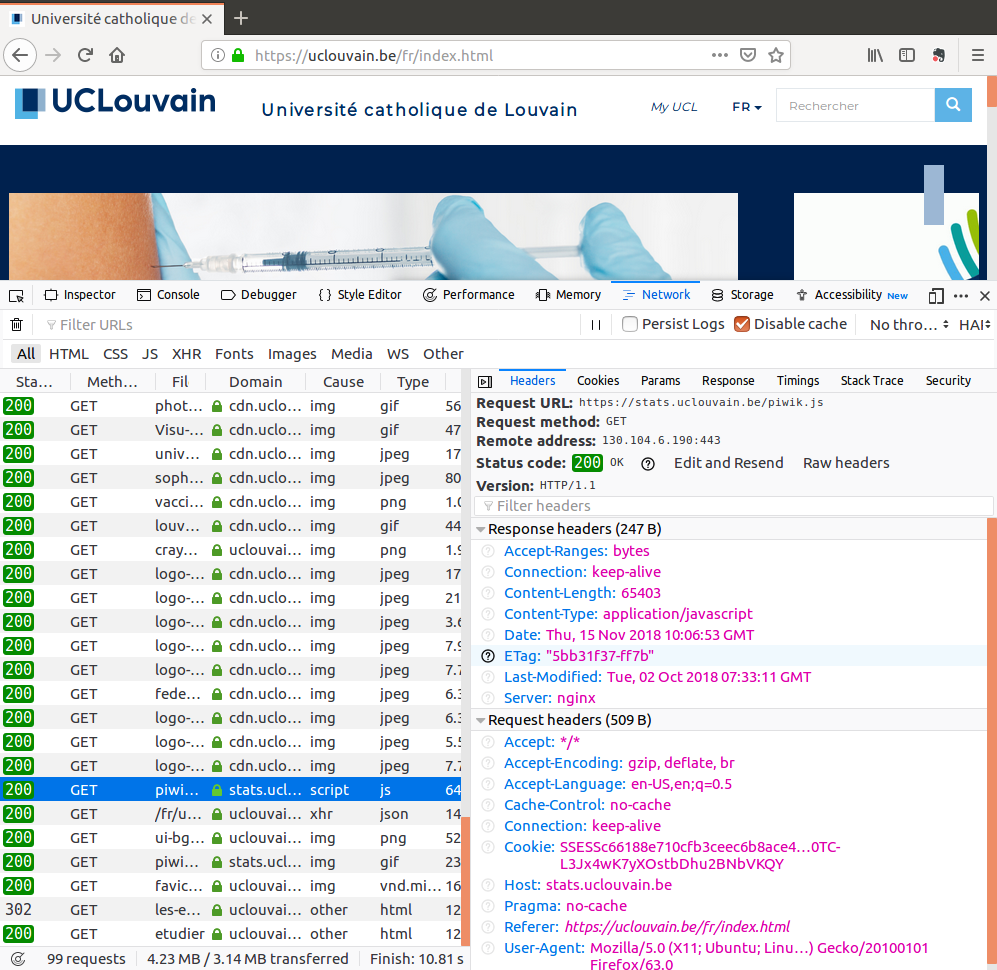
On this web site, the statistics are collected by the piwik software.
The IETF web site also serves all its requests locally and does not depend on third party services. However, it uses the CloudFlare CDN to distribute the load and HTTP/2.0.